
This paper studies the challenge of developing robots capable of understanding under-specified instructions for creating functional object arrangements, such as "set up a dining table for two"; previous arrangement approaches have focused on much more explicit instructions, such as "put object A on the table." We introduce a framework, \( \textit{SetItUp} \), for learning to interpret under-specified instructions. SetItUp takes a small number of training examples and a human-crafted program sketch to uncover arrangement rules for specific scene types. By leveraging an intermediate graph-like representation of \( \textit{abstract spatial relationships} \) among objects, SetItUp decomposes the arrangement problem into two subproblems: i) learning the arrangement patterns from limited data and ii) grounding these abstract relationships into object poses. SetItUp leverages large language models (LLMs) to propose the abstract spatial relationships among objects in novel scenes as the constraints to be satisfied; then, it composes a library of diffusion models associated with these abstract relationships to find object poses that satisfy the constraints. We validate our framework on a dataset comprising study desks, dining tables, and coffee tables, with the results showing superior performance in generating physically plausible, functional, and aesthetically pleasing object arrangements compared to existing models.
Overall architecture of SetItUp. Given a novel instruction \( \textit{desc} \) and a set of objects \( \mathcal{O} \), we first query an LLM to induce an abstract spatial relationship description of the target object arrangements. The input to the LLM also includes a handful of training examples \( \mathcal{D} \) and a human-defined task-family sketch. Next, we ground these abstract relationships into object poses by composing a library of diffusion models to generate object poses that simultaneously comply with all proposed spatial relationships.

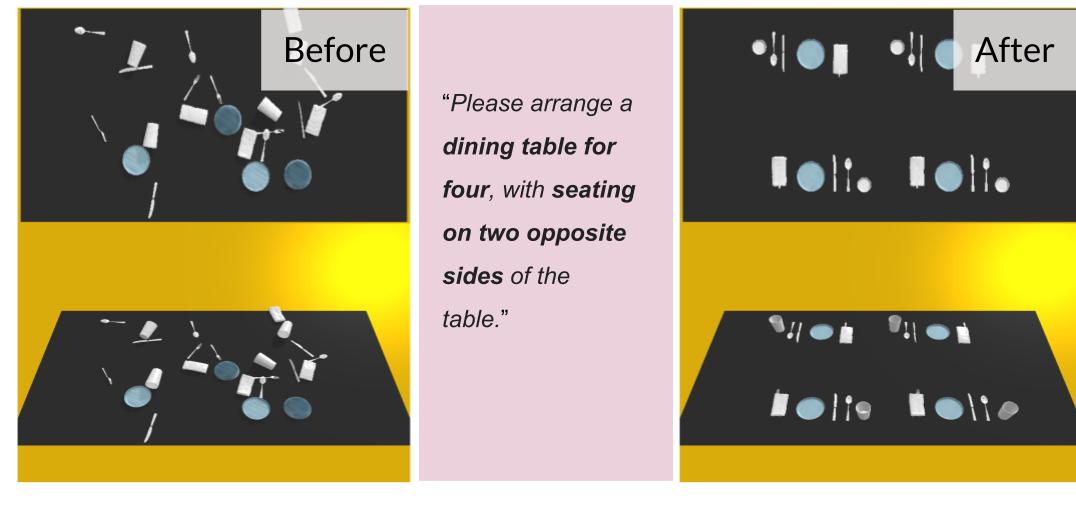

We evaluated SetItUp on three task families, namely study desks, dining tables and coffee tables. They involve different types of objects, different aesthetic patterns, and different types of human needs (\eg, using a laptop vs. paper and pencil, formal dining vs. casual dining). They also progressively increase in scene complexity: the study desk has the fewest objects and important relationships, and the dining table features the most.
Evaluation on the generalization to novel instructions. Details on the seen-unseen splits are provided in the appendix. Our model shows the least amount of performance drop when generalizing to novel instructions.
@inproceedings{xu2024set,
title={"Set It Up!": Functional Object Arrangement with Compositional Generative Models},
author={Yiqing Xu and Jiayuan Mao and Yilun Du and Tomas Lozáno-Pérez and Leslie Pack Kaebling and David Hsu},
year={2024},
booktitle={Robotics: Science and Systems},
}